
nanoGPT-training
This post is written after watching Andrej Karpathy’s Lst’s reproduce GPT-2 (124M) video. I followed along most of the acceleration techniques on Windows platform with a Nvidia 4060 Ti GPU.
Below is a summary table of different techniques Andrej introduced in his video and I also tried to see the performance improvement on my end.
Summary of acceleration statistics
| Acceleration | A100 (tokens/sec) | 4060 TI (tokens/sec) |
|---|---|---|
| Base case | ~16000 | ~1600 |
| TF32 Precision | ~49000 | ~2000 |
| Autocast BF16 | ~54500 | ~3250 |
| Torch Compile | ~126000 | N/A |
| Flash Attention | ~170000 | ~15000 |
| Nice number | ~175000 | ~15300 |
Acceleration approaches
TF32 Precision
TensorFloat-32 (TF32) is a datatype that is used to accelerate FP32 in supported architecture. For instance, as the A100 whitepaper [1] noted, with TF32, it is running 10x faster comparing to V100 FP32 for fused-multiply-add (FMA) operations. Below is the detail of TF32 comparing to other float datatypes:
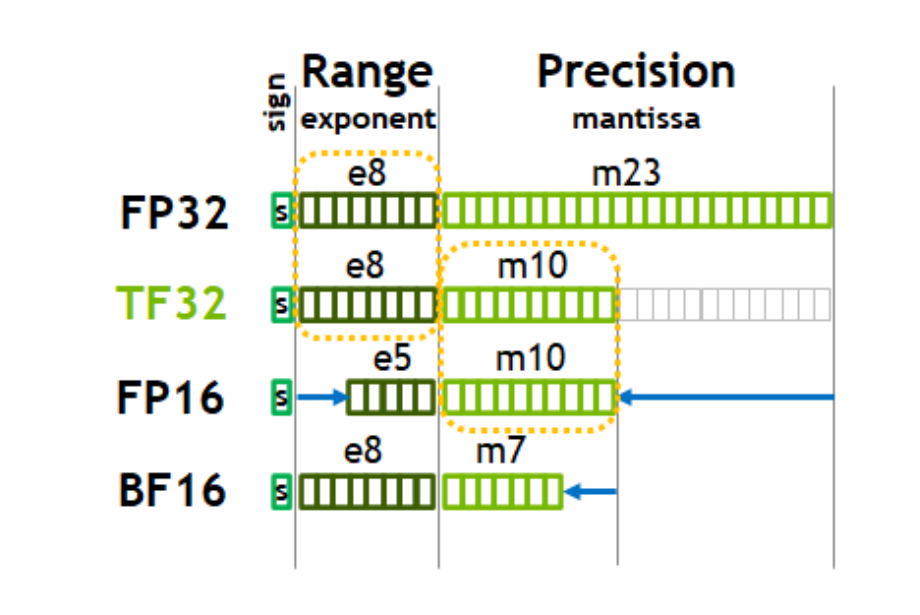
TF32 truncated mantissa bits when compard to FP32. This will help to accelerate calculations traded with the reduction in precision. For most of the time, the impact could be negligible [2]. It can be simply added as the following:
torch.set_float32_matmul_precision('high')
Autocast BF16
PyTorch provides convenience methods for using mixed precision via torch.amp API [3]. While the previous section deals with FMA operations, automatic mixed precision provides us a way to lower precision (FP16 or BF16) for feasible ops, such as linear layers and convolution layers. A lot of other ops often require higher precision, for instance, layernorm and softmax operations. BF16 is usually preferred since it has the same exponent bits as FP32 and TF32. This means that it can represent the same range as TF32 and FP32 with lower precision, and it can be directly truncated from FP32 or TF32.
# optimize
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
for i in range(50):
t0 = time.time()
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
with torch.autocast(device_type=device, dtype=torch.bfloat16): # Automatic Mixed Precision
logits, loss = model(x, y)
loss.backward()
optimizer.step()
torch.cuda.synchronize()
t1 = time.time()
dt = (t1 - t0) * 1000 # time difference in ms
tokens_per_sec = (train_loader.B * train_loader.T) / (t1 - t0)
print(f"step {i}, loss: {loss.item()}, dt: {dt:.2f}ms, tok/sec: {tokens_per_sec:.2f}")
Torch Compile
torch.compile helps to speed up PyTorch code by compiling the codes into optimized kernels, which can reduce read/write on GPU with kernel fusion. Unfortunately, it is not well supported on Windows platform so I did not make a try. However, from the A100 statistics in the original tuturial, the improvement with torch.compile is a lot!
Flash Attention
Flash attention [4] was introduced in 2022 and aim to reduce the memory footprint of the attention mechanism. It helps to reduce the reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM.
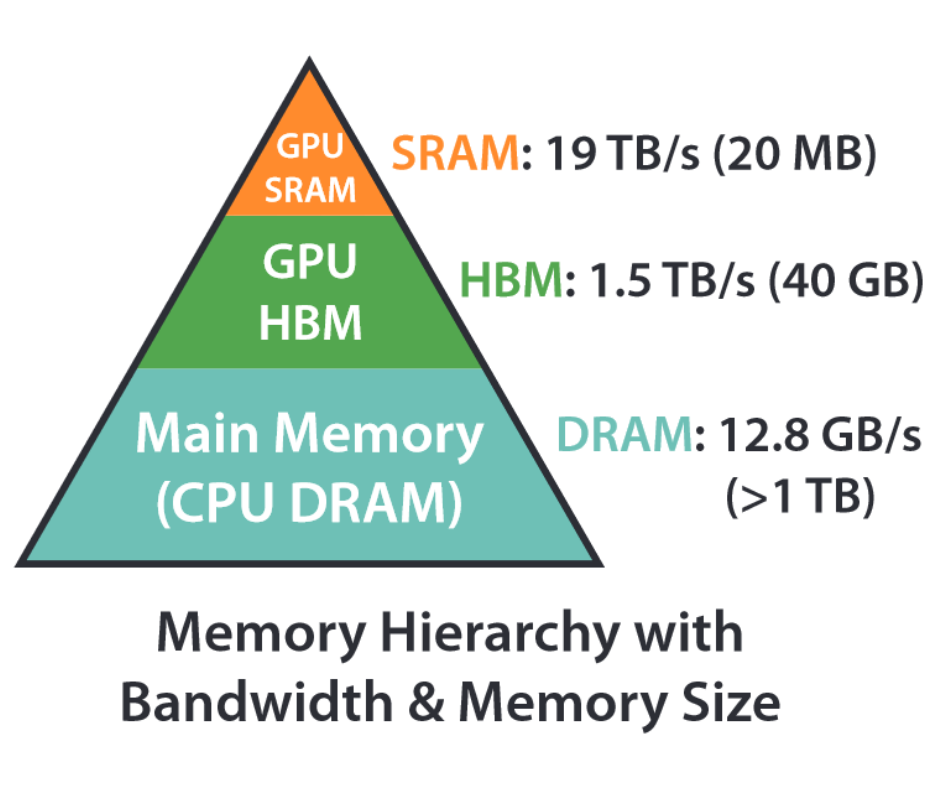
As shown from the flash attention paper above [4], on-chip GPU SRAM has a much higher bandwidth comparing to the HBM. It also turns out that usually attention calculations are memory-bound calculations meaning that compuatation runs faster than moving the data betwen HBM and SRAM. Therefore, by reducing the reads/writes with HBM, we can massively reduce the latency from the slower communication between HBM and on-chip SRAM. Flash attention itself deserves another post to discuss but here is a simple line in PyTorch to use it rather than our vanilly implementation from the previous pose:
# Forward function inside CausalSelfAttention
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
## vanilla implementation
# att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(q.shape[-1])) # (B, nh, T, T)
# att = torch.masked_fill(att, self.bias[:,:,:T,:T] == 0, float('-inf'))
# att = F.softmax(att, dim=-1)
# y = att @ v # (B, nh, T, hs)
# Flash Attention
y = F.scaled_dot_product_attention(q, k, v, is_causal=True)
y = y.transpose(1, 2).contiguous().view(B, T, C) # (B, T, C) rearrange number of heads together
y = self.c_proj(y)
return y
Change Ugly Numbers
Another simple trick is to make the power of 2 your friend.
@dataclass
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50274 # GPT-2 vocab_size of 50257, round to nearest multiple of 64
n_layer: int = 12
n_head: int = 12
n_embd: int = 768
From the original GPT-2 tokenizer, the vocabulary size is 50257 which is not divisible by 2. If not, all the kinds of boundary protection and conditional statements will happen in GPU and slow down the process. By changing the vocabulary size to the nearest multiple of 64, it does help to accelerate the model. However, it should be noticed that by rounding up, we are increasing the size of weight of the token embedding matrix and the final linear layer. Based on the test results, the benefit of rounding up the vocabulary size covered the extra calculation in matrix multiplication.
Reference
[1] NVIDIA A100 Tensor Core GPU Achitecture, 2020. https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf
[2] torch.set_float32_matmul_precision — PyTorch 2.6 documentation. (n.d.). https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html
[3] Automatic Mixed Precision package - torch.amp — PyTorch 2.6 documentation. (n.d.). https://pytorch.org/docs/stable/amp.html#automatic-mixed-precision-package-torch-amp
[4] Dao, T., Fu, D., Ermon, S., Rudra, A., & Ré, C. (2022). Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35, 16344-16359.